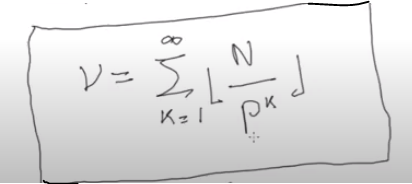Famigliarizziamo con gli operatori Bitwise
Un trucco nella manipolazioni Bitwise. Consideriamo un qualunque numero N ≥ 1, supponiamo che abbia una certa rappresentazione binaria,che rappresenta in binario(sequenza di bit es 1000100)un certo valore in questo caso il nostro N. Se fossimo interessati al seguente problema:
1) Determinare il valore del bit che si trova all'estrema destra, cioè il bit meno significativo(LSB (Least Significant Bit, bit con peso minore). Invece il bit all'estrema sinistra è il più significativo(MSB (Most Significant Bit, bit con peso maggiore).
Questo problema lo possiamo risolvere utilizzando gli operatori logici. Si vuole determinare il primo 1 partendo da destra (LSB) cioè il rightmost set bit. A questo scopo si utilizza l'AND con il numero 1,in modo da far venire tutti zeri a sinistra del bit che voglio determinare. Quindi utilizzo : N AND 1 se utilizzo VBnet.
Invece in C# si usa N & 1. Ed ottengo il valore del bit all'estrema destra(LSB) perchè otteniamo 0 o 1, viene 0 se N aveva 0 all'estrema destra e viene 1 se N aveva all'estrema 1. In questo modo elegante riusciamo ad ottenere quanto richiesto con un semplice operatore AND & 1. Dal punto di vista pratico questo risultato può essere rappresentato in questo modo:
1) Se il numero all'estrema destra è 1 ⤍ Dispari
2) Se il numero all'estrema destra è 0 ⤍ Pari
Perché ciò che fa il numero( in questo caso N)pari o disapari è proprio l'ultimo numero, in quanto negli altri numeri posso sempre tirare fuori il 2 come fattore. Quindi i numeri a sinistra del LSB sono sempre pari e diventano dispari proprio o rimangono pari proprio in virtù del valore che assume il bit all'estrema destra(LSB).
2) Determinare il conteggio dei bit = 1(set bit) nella rappresentazione binaria di N.
Cioè come in questo esempio fatto a mano, mi calcolo il numero di bit = 1. Vogliamo scrivere un algoritmo che sia in grado di restituirci questo risultato.
Una prima idea, più semplice e Naive è quella di andare a sfruttare questa capacità che abbiamo di andare a vedere qual'è il valore del bit all'estrema destra. E poi schiftiamo via via questo numero e controlliamo quanto vale quest cifra all'estrema destra se vale 1 cumuleremo una nuova unità se è zero non lo conteremo. Possiamo utilizzare l'operatore di shift verso destra e poi andare a vedere tra con l'AND tra l'N e 1 il bit all'estrema destra.
Alla fine mi ritroverò con tutti zeri. Quindi:
l'algoritmo Naive ⤍ consiste nel prende il numero, andare a fare l'And tra il numero e 1 ovvero N AND 1 per vedere se l'ultimo bit è 0 o 1 e via via shitfare verso destra fin quando arriviamo ad un N = 0.
Vediamo un modo più efficiente di contare i bit attraverso:
l'algoritmo di Kernighan ⤍ che utilizza N AND N-1, riduce notevolmente il numero di passaggi, in quanto diventano pari al numeri di bit=1 che ci sono dentro al numero N. Non facciamo più un numero di passaggi pari al numero totale di bit che ci sono nella rappresentazione binaria del numero, come nell'algoritmo Naive. Ma stiamo facendo un numero di passaggi che è uguale al
numero di bit = 1 che ci sono nella rappresentazione binaria del numero. Quindi l'N AND N-1 va a resettare il bit=1 più a destra e così via via in loop. Cioè significa fare il loop dove faccio un AND tra N e N-1 e si fa un unset (resetta) del bit = 1 che si trova nell'estrema destra. Quando gli ho azzerati tutti cioè N = 0,vuol dire che ho finito. Basta contare quante volte giro nel loop e mi da il numero di bit = 1.
Un altro problema classico elegantemente risolto dagli operatori Bitwise è il seguente:
3)Determinare la più grande potenza di 2 esempio 2^k che divide N. Cioè vogliamo essere in grado di esprimere N nella seguente forma :
Come una certa potenza di due moltiplicato per l'intero dispari che che residua come fattore. A questo scopo si utilizza l’operatore bitwise AND tra il numero N in questione e il numero NOT N-1. Cioè sarà:
Soluzione elegante, dove in un colpo solo andiamo a risolvere questo problema senza nessun loop.
4)Determinare la massima potenza di 2 che divide un numero n fattoriale, dove n≥1 è un intero.
Cioè si vuole scrivere n fattoriale come: n! = 2^𝞶 * D, dove D è un numero dispari.
A tale scopo si utilizza la formula di Legendre che ci darà come risultato esattamente 𝞶 a cui siamo interessati. 𝞶 sarà la valutazione duatica di n!
Cioè dato un n! ci da la massima potenza di p che divide n!. cioè ci da il proprio quel 𝞶 t.c
Una semplificazione si ottiene quando n è una potenza di 2 e quindi si ha che 𝞶 è esattamente n-1